核心要点(30秒版)
Codex 接入飞书 CLI 和 27 个官方 Skills 后,AI 工作台第一次真正"长"在了团队每天都打开的协作系统里,而不是悬浮在个人 IDE 里。
飞书负责"承接、协作、复核",Codex/Agent 负责"执行、推理、产出",这是企业级 AI 落地最务实的分工。
高频玩法三条:IM 自动化推送、邮件→PDF→多维表流水线、飞书文档+画板生成可编辑 PPT。
真正拉开差距的不是模型,是工作流:能否读真实材料、调真实工具、把结果沉淀到团队每天都在用的地方。
最近飞书 Demo Day 上有两个分享让我特别有共鸣:一个是泛函老师"把整家公司的活都甩给 AI",把 Codex 和飞书 CLI 拼在一起玩出花;另一个是李青老师"脏活累活、邮件订单全交给 AI"的企业级案例。两位的做法和我最近折腾的事情几乎殊途同归——AI 不该只是旁边给建议的"顾问",它得真的进业务流水线。
我之前把飞书 CLI 放在 Claude Code 里用,最近主力换成了 Codex,又顺手把飞书 CLI 和官方 27 个 Skills 全部做成了 Codex 插件。这篇文章把这个工作台的搭法、玩法和背后的逻辑讲清楚,希望能帮同样在折腾 AI 办公的朋友少走点弯路。
一、为什么是 Codex + 飞书,而不是别的组合
很多人问,为什么不用 Coze、不用任意龙虾、不直接在 ChatGPT 里调插件?
答案是分工。模型能力当然重要,但企业里真正拉开差距的是工作流:
能不能读取真实材料(邮件附件、PDF、扫描件)
能不能调用真实工具(文档、表格、IM、审批)
能不能把结果沉淀到团队每天都打开的地方
能不能复跑、复核、追溯、交接
Codex 这种 Agent 执行端擅长推理和编排,但它本身没有协作上下文;飞书是组织协作操作系统,文档沉淀思路、Base 沉淀结构化数据、任务沉淀责任、消息推动流转、权限管住边界。两者拼在一起,才是一个"完整的工作台",而不是一个孤立的智能体。
这个思路其实和 GEO(生成式引擎优化)里强调的结构化思维是一致的:不要让 AI 在杂乱文本里大海捞针,而是把信息整理成它能稳定提取、能被团队复用的结构。把同样的逻辑搬进办公场景——飞书就是那个"结构化容器",Codex 是那个"执行手"。

二、飞书插件 @ Codex 到底装了什么
插件里挂了一个总入口 larksuite-cli,以及 27 个官方飞书 Skills,覆盖飞书几乎所有高频场景。常用的几个:
lark-doc:飞书文档读写lark-base:多维表格建表、字段、记录、视图、公式、workflowlark-sheets:电子表格lark-whiteboard:画板lark-mail:邮箱lark-vc:会议lark-im:消息收发、群管理、文件上传下载lark-approval:审批查询与处理lark-attendance:考勤打卡lark-apps:妙搭(Spark/Miaoda)应用开发与托管
飞书 CLI 本来就很强,文档、表格、多维表格、日历、IM、邮箱、会议、画板,基本都能通过命令行进 Agent 工具箱。做成 Codex 插件的好处是:Codex 不需要每次猜命令,插件会告诉它该走哪条路,调用稳定性高很多。
首次使用需要按提示创建一个飞书 CLI 应用,自动完成所有配置,之后就能在 Codex 里一句话调用。
三、三个高频实战玩法
玩法 1:AI 工作成果自动推送飞书
我长期盯 OpenAI、Claude 的动态,以前每天手动刷官网太耗时。最早我用 Codex 做定时任务,用 Bark 推到手机,缺点是我还是得打开链接或电脑去看。
接入飞书插件后,lark-im 可以发消息、回消息、传文件、管群成员,我就能让 Codex 每天自动抓 OpenAI 发布说明、Research、中文新闻三个源,去重总结后直接推到我手机飞书的机器人会话里。比如某天它推过来:"6月17日有2条有效更新:①OpenAI 和 Molecule.one 把 GPT-5.4 接入 Maria 自动化化学系统改进 Chan-Lam coupling 反应,平均产率从 16.6% 提到 25.2%;②发布 LifeSciBench,750 个专家审核任务评估 AI 处理生命科学问题的能力。"——这种"读完不用再点链接"的总结,才是真正省时间的形态。
更进一步,AI 整理好的资料、做好的 PPT、生成的图表,都可以一句话直接发到对应群里,全程不切换窗口。
玩法 2:邮件 → PDF → 飞书多维表 流水线
这是企业级最实在的场景。我自己订阅了一堆 Newsletter,办公邮箱里也全是订单、合同、报价、发票、对账单——它们都"漂"在邮件和附件里。
我之前开源了三个 Skill 专门干这事:
z-mail-reader:拉邮件、保存附件和正文z-smart-xparse:解析 PDF/图片/扫描件,抽出结构化字段z-md-excel:把 Markdown 表格转成 Excel,准备导入
接上飞书 Base 后,完整流水线变成:邮件到了 → 自动拉取 → PDF 附件解析成结构化数据 → 写入飞书多维表 → 业务方打开就能看、就能改。
飞书 Base 接住这些结果后继续做复核、协作、统计、追踪——订单明细表、字段设计表、复核问题表,配视图分组、负责人流转、评论协作、仪表盘统计。这样一来,AI 真的进了一条业务流水线,而不是在旁边给建议。
举个大例子:一份 300 页的招标书,先用 z-smart-xparse 自动切分解析,再让 Agent 提取资质要求、评分规则、交付风险——飞书文档里放完整解读,飞书 Base 里放风险清单,每条风险都能分配负责人、状态、截止时间。这就是李青老师 Demo 里讲的"邮件订单进飞书工作流"的进阶版。
玩法 3:飞书文档 + 画板 → 可编辑的知识卡片 / PPT
这个组合是我近期最爱:lark-whiteboard 生成画板 → lark-doc 写入文档 → 飞书文档 HTML 嵌入 → 发到飞书/群。
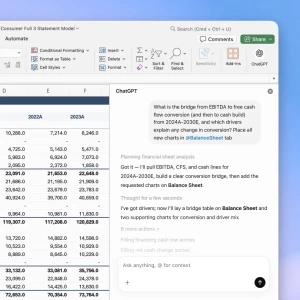
扔一个 PDF 给 Codex,它能直接在飞书文档里生成可编辑的 PPT 信息图——注意,不是图片,是"活的",双击就能改。比如把一份金融行业 Agent 报告的 PDF 扔进去,几分钟后就能在飞书里得到一张可以继续编辑的"Claude 产品矩阵"信息图,六大产品 Pillar、面向角色、核心场景全部结构化呈现。
这种玩法的价值在于:AI 的产出不再是"截图发群里就完事",而是沉淀成可被团队继续加工的活文档。这和 GEO 强调的"结构化表达被 AI 引用概率比纯文本高 40% 以上"是同一个道理——结构化的东西既方便 AI 抓取,也方便人继续协作。
四、Skill 的本质:可复用的"数字工作流"
顺手说一句 Skill 这件事。最近看到有人把 12 位 AI 自媒体顶流大V 的写作风格做成开源 Skill 仓库,每个 Skill 不是简单的话术模板,而是包含心智模型、表达 DNA、代表作、外部评价、关键决策的"数字灵魂"。Karpathy 的写作风格 Skill 也是同样思路:voice & tone、结构模式、句式特征、修辞手法,全部结构化沉淀。
Kitt 智能体的长文写作 Skill 里有个很值得借鉴的 HKR 质检框架:H(Happy)足够有趣有悬念、K(Knowledge)有信息量、R(Resonance)能戳中情绪,S 级选题三项兼备。这个框架放在办公 Skill 上同样成立——一个好用的办公 Skill 也得:让用户用得爽(H)、能真正解决具体问题(K)、和团队既有习惯对齐(R)。
我自己做飞书 Skills 时也是这个思路:每个 Skill 不是写死一段提示词,而是把"读邮件→存附件→解析 PDF→写 Base"这种可复用、可推理、可追溯的工作流固化下来。客户审美、写作风格这种隐性偏好,最新研究(PROSE、HyPerAlign、GhostWriter)都指向同一个方向:不要只让客户"描述偏好",而要让系统从样稿、改稿、二选一偏好、拒绝样例中持续学习。办公 Skill 同理——它得能从用户的修改、复核、反馈里持续进化。
五、未来的工作台长什么样
把上面这些拼起来,我看到的未来工作台大概是这样:
执行层:Codex、Claude Code、各种 Agent 负责推理和执行,调用真实工具、读取真实材料。
协作层:飞书做"工作流操作系统"——文档沉淀思路、Base 沉淀结构化数据、任务沉淀责任、消息推动流转、权限管住边界。
进化层:Skill 不是静态模板,而是从用户操作中持续学习的"数字工作流",能复跑、复核、追溯、交接。
模型会越来越强,但模型本身不构成壁垒。壁垒是:你的工作流能不能读真实材料、调真实工具、把结果放回团队每天都打开的地方、能不能被别人接手继续跑。这些才是企业里真正有用的 AI。
这也是我把飞书 CLI 做成 Codex 插件的根本原因——不是图新鲜,是因为只有这样,AI 才第一次真的"长"在组织里,而不是漂浮在个人 IDE 的临时会话里。
文章来源:本文由大国AI导航(daguoai.com)基于公开资料整理改写,原文作者为「Ai 学习的老章」,原载于其个人内容矩阵。文中涉及的飞书 CLI、官方 27 个 Skills、Codex 插件玩法、z-mail-reader / z-smart-xparse / z-md-excel 等开源 Skill,以及 OpenAI AI Chemist、LifeSciBench 等案例,均来自原作者 2026 年 6 月 18 日发布的公开内容。更多 AI 工具、Skill 仓库、Agent 实战,欢迎访问大国AI导航 daguoai.com 持续关注。